小编:Home 6月17日报告说,Minimax Xiyu Technology宣布将连续五天发布重要的更新。今天的第一个炸弹是开放资源
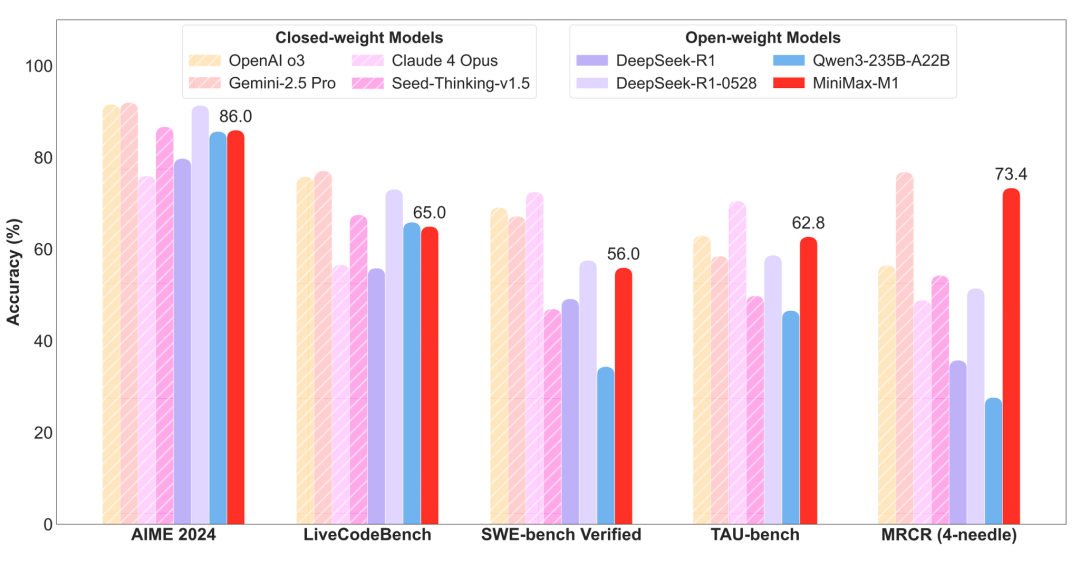 Home 6月17日报告说,Minimax Xiyu Technology宣布将连续五天发布重要的更新。当今的第一个炸弹是第一个开放资源推理最小值M1模型。根据官方介绍,Minimax-M1是大规模混合体系结构推理模型的第一个开源。 Minimax说:M1功能是复杂生产力的情况下最好的开放式模型,这些模型超过了国内资源模型,在国外的顶级模型附近,与此同时,它在该行业中的有效性最高。该官方博客还指出,最小值-M1培训过程的两种主要技术很棒,并且“超出了预期”。仅需3周和512 H800 GPUTO即可完成刺激训练阶段。计算电源成本的成本仅为534,700美元(在家注释:当前汇率约为384.1万元),直接低于初步期望。 M1 ha这是一个重要的优势,它支持该行业环境中最高的100万个背景,这是Deptseek R1的8倍,例如封闭源模型,是80,000个令牌行业的最长推理产出。这主要是因为我们基于闪电注意机制的原始混合体系结构,在计算长上下文输入和深层推理时,这可能非常好。例如,在深层推理中使用80,000个令牌时,您只需要使用DeepSeek R1的计算强度约为30%。在训练和推理时,此功能比计算能力的效率相比,我们具有巨大的优势。此外,我们建议使用更快的增强研究算法,以通过减少采样权重的重要性(而不是传统的令牌更新)来提高研究增强的技能。在AIME实验中,我们发现它的速度是刺激研究算法(例如DAPO)的两倍,包括字节,这是符号比Deviceek在早期使用的GRPO好。多亏了以上两种创新技术,我们的最终培训过程非常出色,超出了期望。实际上,整个增强研究的阶段在三周内只有512 H800块,以及租用Isonly 534,700美元的费用。这是最初比预期的数量级。我们已经在17个主要的工业审查集中审查了M1,具体结果如下:我们发现,我们的模型对复杂的生产力风景(例如软件工程,长篇小说和工具使用)具有重要好处。 Minimax-M1-40K和Minimax-M1-80K在SWE Bench验证基准上取得了55.6%和56.0%的效果,这略低于其他开放的重量资源。I-Type依赖于其百万级的上下文的窗口,该系列的M1系列超过了所有的开放式体重损失模型,但在一般而言的OPER中,甚至超过了Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla。4 Opus在世界上排名动态,并以略有空间抓住了Gemini 2.5 Pro的背后。在使用代理工具(TAU基础)的情况下,Minimax-M1-40K也带领所有开放式重量模型并击败Gemini-7.5 Pro。值得注意的是,在大多数基准测试中,Minimax-M1-80K始终优于最小值-M1-40K,这在扩展测试时已经充分证明了计算资源的有效性。详细的技术报告,可以在我们的官方面部拥抱和GitHub帐户下访问完整的模型权重。两个开放的资源项目VLLM和Transformers提供了推理的依据,我们还在Sglang工作以促进扩展支持。由于相对出色的培训和使用计算强度的推断,我们维持了无限制,Libreng使用Minimax App和Web,并以行业最低的价格向官方网站提供API。当输入长度为0-32K时,插入0.8元 /百万个令牌,输出8元 /百万令牌当输入长度为32k-128k时,输入1.2元 /百万个令牌,并输出16元 /百万个令牌;当输入长度为128k-1m时,输入2.4元 /百万个令牌,并输出24元 /百万个令牌。前两种模式都比DeepSeek-R1更有效,而后期模式不受DeepSeek模型的支持。除M1外,我们还在接下来的四个连续工作日为每个人准备了一些更新,因此请保持专注。
Home 6月17日报告说,Minimax Xiyu Technology宣布将连续五天发布重要的更新。当今的第一个炸弹是第一个开放资源推理最小值M1模型。根据官方介绍,Minimax-M1是大规模混合体系结构推理模型的第一个开源。 Minimax说:M1功能是复杂生产力的情况下最好的开放式模型,这些模型超过了国内资源模型,在国外的顶级模型附近,与此同时,它在该行业中的有效性最高。该官方博客还指出,最小值-M1培训过程的两种主要技术很棒,并且“超出了预期”。仅需3周和512 H800 GPUTO即可完成刺激训练阶段。计算电源成本的成本仅为534,700美元(在家注释:当前汇率约为384.1万元),直接低于初步期望。 M1 ha这是一个重要的优势,它支持该行业环境中最高的100万个背景,这是Deptseek R1的8倍,例如封闭源模型,是80,000个令牌行业的最长推理产出。这主要是因为我们基于闪电注意机制的原始混合体系结构,在计算长上下文输入和深层推理时,这可能非常好。例如,在深层推理中使用80,000个令牌时,您只需要使用DeepSeek R1的计算强度约为30%。在训练和推理时,此功能比计算能力的效率相比,我们具有巨大的优势。此外,我们建议使用更快的增强研究算法,以通过减少采样权重的重要性(而不是传统的令牌更新)来提高研究增强的技能。在AIME实验中,我们发现它的速度是刺激研究算法(例如DAPO)的两倍,包括字节,这是符号比Deviceek在早期使用的GRPO好。多亏了以上两种创新技术,我们的最终培训过程非常出色,超出了期望。实际上,整个增强研究的阶段在三周内只有512 H800块,以及租用Isonly 534,700美元的费用。这是最初比预期的数量级。我们已经在17个主要的工业审查集中审查了M1,具体结果如下:我们发现,我们的模型对复杂的生产力风景(例如软件工程,长篇小说和工具使用)具有重要好处。 Minimax-M1-40K和Minimax-M1-80K在SWE Bench验证基准上取得了55.6%和56.0%的效果,这略低于其他开放的重量资源。I-Type依赖于其百万级的上下文的窗口,该系列的M1系列超过了所有的开放式体重损失模型,但在一般而言的OPER中,甚至超过了Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla and Cla。4 Opus在世界上排名动态,并以略有空间抓住了Gemini 2.5 Pro的背后。在使用代理工具(TAU基础)的情况下,Minimax-M1-40K也带领所有开放式重量模型并击败Gemini-7.5 Pro。值得注意的是,在大多数基准测试中,Minimax-M1-80K始终优于最小值-M1-40K,这在扩展测试时已经充分证明了计算资源的有效性。详细的技术报告,可以在我们的官方面部拥抱和GitHub帐户下访问完整的模型权重。两个开放的资源项目VLLM和Transformers提供了推理的依据,我们还在Sglang工作以促进扩展支持。由于相对出色的培训和使用计算强度的推断,我们维持了无限制,Libreng使用Minimax App和Web,并以行业最低的价格向官方网站提供API。当输入长度为0-32K时,插入0.8元 /百万个令牌,输出8元 /百万令牌当输入长度为32k-128k时,输入1.2元 /百万个令牌,并输出16元 /百万个令牌;当输入长度为128k-1m时,输入2.4元 /百万个令牌,并输出24元 /百万个令牌。前两种模式都比DeepSeek-R1更有效,而后期模式不受DeepSeek模型的支持。除M1外,我们还在接下来的四个连续工作日为每个人准备了一些更新,因此请保持专注。
当前网址:https://www.h-f-a.com//experience/share/2025/0619/179.html